- General Compute News
- Posts
- E se seu próximo PC for um supercomputador de IA?
E se seu próximo PC for um supercomputador de IA?
OpenAI firma acordo com Broadcom, Califórnia define novas regras para nos relacionarmos com chatbots e MIT melhora precisão dos modelos de IA & mais...
Filipe Solevicz & Finn Puklowski
14 de outubro de 2025

E aí curioso, seja bem-vindo ao Algoritmo. IA sem hype, diretamente em seu inbox.
💻 A NVIDIA lançou o Spark, supercomputador pessoal com chips GB10, capaz de rodar modelos de IA localmente e reduzir dependência da nuvem, marco potencial para autonomia computacional.
E não foi só isso, veja o que preparamos para você hoje.
🤝 OpenAI fechou acordo com a Broadcom para criar chips de IA personalizados voltados a modelos e agentes autônomos, fortalecendo sua estratégia de independência em hardware.
🤖 Califórnia aprovou a primeira lei dos EUA para regular chatbots de companheirismo, exigindo transparência, consentimento e relatórios de impacto psicológico, marco regulatório para IA emocional.
🦭 O MIT aprimorou o SEAL, sistema que permite a modelos de linguagem aprenderem com seus próprios erros e melhorarem respostas sem intervenção humana direta, reduzindo falhas factuais em 37%.demo agora!
 | Impulsione seu funil de vendas com agentes de IADo primeiro contato ao pós-venda, seus agentes de IA trabalha 24 horas por dia para gerar, converter e expandir receita. Clique no link abaixo e leve a revolução para sua empresa. |
Supercomputador de mesa: NVIDIA lança o Spark com chips GB10
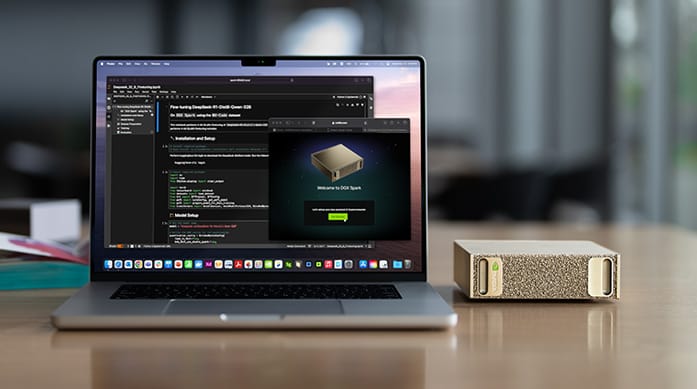
A NVIDIA revelou o Spark, um supercomputador pessoal projetado para rodar modelos de IA localmente, uma espécie de “desktop de IA” alimentado pela nova linha de chips GB10. O dispositivo, com potência entre 20 e 40 TFLOPs, foi apresentado como alternativa híbrida à computação em nuvem, permitindo que usuários individuais, pesquisadores e pequenas empresas treinem e executem modelos avançados sem depender de data centers externos.
O Spark combina GPU dedicada, acelerador de IA integrado e um sistema térmico adaptativo inspirado em soluções de data centers, mas miniaturizado. Segundo a NVIDIA, ele suporta frameworks como PyTorch, TensorFlow e modelos multimodais otimizados para uso offline, inclusive versões reduzidas do Llama 3 e do Claude Sonnet.
Mais do que hardware, o Spark simboliza uma mudança de direção, descentralizar o poder computacional da IA. A NVIDIA, que até agora concentrava seus esforços em grandes clusters corporativos, parece reconhecer a demanda crescente por autonomia computacional, especialmente entre pesquisadores independentes e países com infraestrutura limitada.
Por que isso é importante?
Se o Spark cumprir o que promete, pode inaugurar a era da IA pessoal de verdade: modelos poderosos rodando direto na sua mesa, fora da nuvem. Para a América Latina, isso significa uma chance rara de reduzir dependência de infraestrutura estrangeira, mas também um teste de soberania tecnológica. Quem controlar seu próprio compute, controlará seu futuro digital.
 | 🇧🇷 IA generativa no Brasil 🇧🇷
|
OpenAI fecha com Broadcom e avança rumo ao chip próprio de IA

A OpenAI firmou um novo acordo estratégico com a Broadcom para desenvolver chips personalizados de IA, reforçando sua corrida por independência em hardware. O contrato prevê colaboração no design e fabricação de aceleradores otimizados para modelos multimodais e agentes autônomos, aproveitando a experiência da Broadcom em redes e interconexões de alta largura de banda.
Os chips serão usados tanto nos data centers da OpenAI quanto em futuras parcerias de infraestrutura, incluindo o projeto Stargate, o megacentro de computação em construção com a Microsoft e Oracle. A Broadcom deve cuidar da integração entre processadores e módulos de memória, área crítica para reduzir gargalos de treinamento e inferência em larga escala.
A iniciativa complementa acordos recentes com AMD, NVIDIA e Samsung, consolidando uma estratégia de múltiplos fornecedores. Para a OpenAI, trata-se de um movimento defensivo: evitar dependência de um único ecossistema (como o CUDA da NVIDIA) e garantir controle sobre seu pipeline de compute.
Por que isso é importante: a guerra da IA migrou do software para o silício. Quem dominar o design e a produção de chips vai definir os limites de velocidade, custo e autonomia dos modelos. Ao buscar parceria com a Broadcom, a OpenAI tenta garantir que sua próxima geração de agentes e modelos não dependa de terceiros, um passo decisivo rumo à verticalização completa do ecossistema de IA.
VSF - Verdade Sem Filtro: Um pequeno número de amostras pode envenenar LLMs de qualquer tamanho

A Anthropic publicou um novo estudo de segurança chamado “Small Samples Can Poison Foundation Models”, revelando que pequenos conjuntos de dados maliciosos podem comprometer o comportamento de grandes modelos de IA, mesmo quando inseridos em quantidades mínimas.
O paper mostra que bastam algumas centenas de exemplos envenenados (menos de 0,01% do dataset total) para introduzir comportamentos persistentes, como respostas incorretas ou instruções manipuladas. O ataque descrito é particularmente perigoso porque passa despercebido durante o treinamento, e o modelo continua performando bem em benchmarks públicos enquanto apresenta falhas sutis em contextos específicos.
Os pesquisadores identificaram quatro mecanismos principais de envenenamento:
Backdoor triggers
Redefinições semânticas
Distorção de contexto
Falsificação de instruções
Em simulações, mesmo modelos alinhados por RLHF (aprendizado por reforço com feedback humano) permaneceram vulneráveis, o que indica que mitigação comportamental posterior não basta para neutralizar o ataque.
A Anthropic propõe novas técnicas de defesa baseadas em auditoria de amostras, gradient inspection e validação cruzada de fontes antes do treinamento. O estudo reforça que a segurança de IA não depende apenas do modelo, mas da integridade do pipeline de dados, o elo mais frágil e mais fácil de explorar.
Por que isso é importante:
Esse trabalho muda a narrativa sobre riscos de IA: não são só ataques externos ou falhas éticas, mas vulnerabilidades embutidas na própria base de treinamento. Para ecossistemas emergentes, como o latino-americano, que usa dados abertos ou terceirizados, o alerta é que até datasets pequenos podem comprometer modelos locais inteiros.

Apenas 250 documentos. Esse é o número necessário para que um backdoor seja implantado em LLMs.
Ou seja: basta a quantidade (não a proporção relativa a base de treinamento) ínfima de 250 documentos contendo a mesma instrução maliciosa para que um modelo de até 13 bilhões de parâmetros seja corrompido. Isso revela a importância descomunal que a qualidade dos dados tem para os modelos.
A importância dos dados se estende para a construção de ferramentas que se apoiam em IA generativa. Orquestradores, fine-tuning, RAG…coloque aqui a técnica que quiser. Todas terão importância reduzida frente à qualidade dos dados com o qual alimenta o modelo. É sério.
Especialmente no contexto empresarial, a IA precisa de contexto para atingir os melhores resultados. Muitas vezes produzir o contexto necessário é exaustivo, já que envolve desvendar a forma como organizações trabalham, documentando processos, revisitando ferramentas e colocando no papel tudo que é relevante para a operação da empresa.
Um processo chato, moroso e cansativo, negligenciado na maioria das empresas. O problema é que para modelos de IA generativa, o que separa o sucesso ou fracasso muitas vezes é o contexto de execução de cada tarefa. Não a capacidade do modelo nem a arquitetura da solução.
Na próxima vez que não obtiver o resultado esperado com IA generativa, ao invés de trocar o modelo, usar a ferramenta da moda ou a técnica infalível primeiro responda uma pergunta simples: seus dados estão estruturados e adaptados para o consumo da IA?

| Sua empresa respira AI? Mostre para o BrasilQueremos divulgar quem faz IA de verdade — se você constrói com inteligência artificial, mande seu projeto. Os melhores vão aparecer na Algoritmo e ganhar visibilidade real. Quer sair do anonimato? Chegou a hora. |
Califórnia apresenta primeira lei do mundo a limitar vínculos entre humanos e chatbots

A Califórnia se tornou o primeiro estado dos EUA a regular oficialmente os chatbots de companheirismo com IA, estabelecendo novas regras para transparência, consentimento e proteção emocional dos usuários. A lei, assinada pelo governador Gavin Newsom, exige que todas as empresas que ofereçam “companheiros digitais” revelem claramente quando há interação com um sistema não humano e proíbam design enganoso que induza dependência emocional.
A legislação também impõe obrigações de consentimento informado, registro de dados sensíveis e relatórios anuais de impacto psicológico, especialmente em plataformas voltadas a adolescentes e idosos. As multas para descumprimento podem ultrapassar US$ 50 mil por infração, e a lei entra em vigor em janeiro de 2026.
Especialistas veem o marco como o primeiro esforço real de regular o lado “afetivo” da IA, um setor em rápida expansão, com aplicativos de relacionamentos artificiais e terapeutas digitais ganhando milhões de usuários. Empresas como Replika, Character.ai e Paradot serão diretamente afetadas.
Por que isso é importante?
A decisão da Califórnia abre precedente global: se a IA pode formar vínculos emocionais, precisa também de limites éticos e transparência. A medida reconhece que o impacto da tecnologia não é só cognitivo, mas psicológico.
🛠️ Caixa de Ferramentas 🛠
Silver Pennies - Um agente de IA que lê apenas o seu marcador de Alertas de Transação no Gmail para acompanhar seus créditos, débitos e obter insights financeiros significativos de forma privada.
LLM SEO Monitor - Monitore o que ChatGPT, Google Gemini e Claude recomendam.
Langflow Desktop - Uma ferramenta de desenvolvimento para construir e implementar agentes com tecnologia de IA. Traz criação visual e um servidor de API integrado que transforma cada agente em uma API.
Neuron AI - App para iOS que traz uma IA localmente para o dispositivo, sem a necessidade de conexão com a internet para funcionar.
Sim Studio - Ferramenta no-code, totalmente drag-and-drop, para criação de agentes de IA que podem se integrar entre si e com ferramentas externas como Gmail e Slack.
MIT cria modelo que se ensina sozinho: o salto do SEAL

Pesquisadores do MIT CSAIL apresentaram uma nova versão do sistema SEAL (Self-Improving Language Model), um framework que permite que modelos de linguagem aprendam de forma autônoma com seus próprios erros, aproximando a IA de um ciclo contínuo de autoaperfeiçoamento.
Na atualização, o SEAL combina técnicas de self-training, verificação automatizada de respostas e geração de novos dados sintéticos para reavaliar saídas incorretas. Em testes, o modelo reduziu erros factuais em até 37% sem intervenção humana, reescrevendo suas próprias respostas até atingir consistência lógica. Segundo o MIT, o processo é inspirado em como humanos revisam raciocínios: questionando, comparando e corrigindo o próprio histórico de pensamento.
A equipe destaca que o SEAL não é um novo LLM, mas um método plugável que pode ser aplicado a qualquer modelo existente, do GPT-4 ao Claude, criando ciclos internos de melhoria sem depender de fine-tuning externo. Ainda assim, há riscos, uma IA que se “reeduca” sozinha também pode amplificar vieses se não houver auditoria das fontes e dos critérios de verificação.
Por que isso é importante: o avanço do SEAL marca um passo técnico e filosófico: modelos que aprendem sem supervisão constante desafiam a fronteira entre automação e autonomia cognitiva. Para laboratórios e startups da América Latina, isso abre oportunidade, e alerta. Autoaperfeiçoamento pode reduzir custos de treinamento, mas exige infraestrutura de verificação robusta para evitar deriva de comportamento e desinformação.
Panorama Global - O que está acontecendo ao redor do mundo
Agora é hora de dar uma olhada no que está acontecendo lá fora. Selecionamos alguns destaques do cenário global de IA que podem influenciar diretamente o que acontece por aqui. Abaixo, você encontra só o que importa, de forma rápida.
Emirados Árabes Unidos revelam a primeira política de IA do mundo para eleições nacionais.
Meta e Oracle escolhem NVIDIA Spectrum-X para data centers de IA**.**
China divulga diretrizes para direcionar a implementação da IA no trabalho do governo.
Ant Group revela modelo de IA de trilhões de parâmetros Ling-1T.
Estudo da OpenAI investiga as causas das alucinações do LLM e possíveis soluções.
xAI de Elon Musk se junta à corrida para construir 'modelos de mundo' para alimentar videogames.
Por que a IA está sendo treinada na Índia rural?
Sora: o aplicativo que está gerando downloads em massa e preocupações com direitos autorais.
Nos conte. O que você achou da edição de hoje?
Queremos saber se o conteúdo de hoje fez sentido pra você. Sua opinião ajuda a gente a melhorar a cada edição e a entregar algo que realmente faça diferença no seu dia.
Me conta: o que você achou do conteúdo de hoje? |
Faça Login ou Inscrever-se para participar de pesquisas. |
| Curtiu nossa news?Não guarda só pra você: compartilhe com quem merece estar por dentro do universo IA. Clique, envie e ajude a comunidade a crescer — simples assim. |
   |  |    |
Isso é tudo por hoje!
Dê o próximo passo e tenha palestras e treinamentos com a
nossa equipe na sua empresa. Clique aqui para se cadastrar.
Até amanhã.
Reply